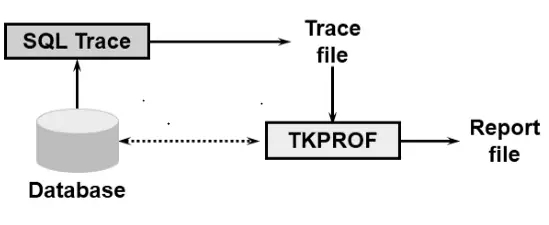
10046 traces and tkprof still save lives and we can use them for old and new versions. But sometimes it will be hard to collect the data if you are trying to help someone who has little oracle knowledge. They have to find the trace folder , identify the trace file and run tkprof…….It is…More
How to install Oracle Linux 8 on GCE using startup scripts
I like to combine existing features to ease my life. There are no public OL images in Google Cloud. But there are Rocky Linux images which are free, open, community enterprise operating system designed to be 100% bug-for-bug compatible with Red Hat Enterprise Linux . And my colleague Andy Colvin from Google mentioned about the…More
From Oracle’s old 248 days bug to Abjad
Most of us spent sleepless nights because of the infamous Bug 10194190 – Solaris: Process spin and/or ASM and DB crash if RAC instance up for > 248 days (Doc ID 10194190.8) . Thanks to Umut Tekin, I learned the reason of this bug and its effects on airplanes from David Malan‘s great lecture .…More
Mind The Gap in APEX graph : nonexistent values in time series and model clause

As always, it seemed so easy at the beginning. Just graph a table on APEX. Nobody told about the gaps in the data 🙂 To make the case simple , lets create a table with 3 columns. Name ,date and value: NM DT VL ali 13.1.2017 5 ali 14.1.2017 3 veli 14.1.2017 4 veli 16.1.2017…More
Finding out the tables in a query: a free SQLParser
We have hundreds of free-hand ,’ quick and dirty’ , MicroStrategy reports and we need to find out the tables that are accessed from them. Most of the queries exceed hundreds of lines , with clauses,views, inline views ,etc… The db is 11.2.0.4. So, the ‘quick and dirty’ way seems as using oracle dbms_sql.parse …More
Calculating TPS from ASH via SQL_EXEC_ID
After a problem happened in an application server running to a 11.2.0.4 database , we were arguing about how many queries per second had been running at the time of the problem for a sqlid . The dba_hist_sqlstat was actually not satisfactory because the snapshot period was 1 hour. The problem started at 23:45 and…More
ORA_HASH and NLS CHARACTERSET to compare code
Task : Find out whether a system trigger or procedure is same in 100+ databases. First idea : Let’s use ORA_HASH for the source code. Action 1: Use LISTAGG to create a single line of data from dba_source. Get rid of the spaces. Action 2: Then use it input to ORA_HASH . And here comes…More
External tables with symbolic links (DISABLE_DIRECTORY_LINK_CHECK)
The first question that was popped up in my mind when I started to use external tables in 10g days was: “Why doesn’t oracle let us use symbolic links?” Everybody was mentioning about security issues. If the DBA is the only one to have access to the oracle machine, there may be a pardon for…More
Pivoting Sqlplus output of a single row in multiple columns with column command
When there are so many columns to fit in a screen for a single row , you may experience difficulties like this one: 13:23:53 SYSTEM@NODS 10-DEC-14 SQL> select * from gv$session where inst_id=1 and sid=479; INST_ID SADDR SID SERIAL# AUDSID PADDR USER# USERNAME COMMAND OWNERID TADDR LOCKWAIT STATUS SERVER SCHEMA# ———- —————- ———- ———-…More
ipmitool to measure electricity usage of Exadata
If you’re curious about the electricity usage of an exadata rack ( or have shortage of power in your data center) you may try to use a smart PDU. But there is a better and cheaper way to measure it by using the ipmitool. After the collection, it’s so easy to create a graph and compare…More
